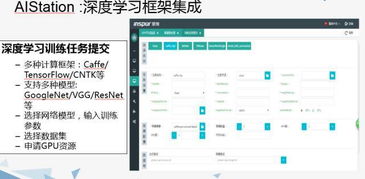
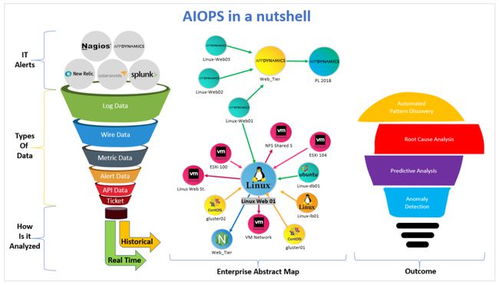
在人工智能領域,賦予機器類似人類的常識推理能力一直是核心挑戰。常識指人類通過與世界互動獲得的基本知識,如‘水往低處流’或‘尖銳物體會刺傷人’。這類知識看似簡單,但對AI系統而言卻極為復雜,因為常識涉及上下文理解、背景知識和經驗推斷。基礎軟件開發是實現這一目標的關鍵,以下探討幾種核心方法。
構建大規模常識知識圖譜是基礎。通過整合來自百科全書、日常對話和物理世界的結構化數據,軟件可以編碼實體間的關系(如‘貓是哺乳動物’或‘火會導致燒傷’)。開發者使用自然語言處理(NLP)技術從文本中提取常識,并利用圖數據庫存儲,使AI能進行邏輯推理。例如,如果系統知道‘雨會弄濕衣服’,它就能推斷出‘雨天應帶傘’。
強化學習和交互式環境訓練可模擬人類學習過程。基礎軟件可以集成模擬器(如虛擬家庭或城市),讓AI代理通過試錯學習常識規則。例如,在模擬中,AI可能發現‘觸摸熱爐會受傷’,從而形成因果知識。這種方法減少了依賴純數據驅動模型,轉而強調經驗積累。
多模態學習整合視覺、語言和感官數據。人類常識源于多種感官輸入,基礎軟件需支持跨模態模型,例如將圖像中的‘冰是冷的’與文本描述關聯。深度學習框架如Transformer已用于融合這些數據,提升AI的情境理解能力。
挑戰依然存在:常識的模糊性和文化差異可能導致偏差,而計算資源需求高。基礎軟件開發需聚焦可擴展架構、倫理對齊和持續學習機制。通過結合知識工程、機器學習和認知科學,我們正逐步縮小AI與人類常識的差距,推動更智能、可信的系統誕生。